Branching avec git
Les ninjas utilisent Git depuis la création de Ninja Squad pour tous leurs projets. Le site web de Ninja Squad est sous Git. Ce blog est géré avec Git. Nos formations sont sous Git.
Néanmoins, depuis que nous l'utilisons chez notre client, sur un projet de développement complexe, avec plusieurs branches développées et maintenues en parallèle, nous avons encore développé notre git-fu.
Les différentes manières de développer de nouvelles fonctionnalités en utilisant des branches Git sont bien documentées, et font l'objet d'une littérature abondante. L'utilisation de branches de maintenance est, elle, assez peu décrite, et nous avons dû trouver un mode de travail pour les gérer.
Mais commençons par le début, et décrivons comment nous avons décidé de travailler avec la branche de travail principale : master.
Développer une nouvelle fonctionnalité
Plonger dans l'historique d'un projet et régler des conflits est déjà bien assez compliqué. Lorsque l'historique n'est pas linéaire, mais constitué de nombreuses branches fusionnées les unes dans les autres, c'est encore plus compliqué. Nous avons donc choisi un mode de travail nous assurant un historique le plus linéaire possible, similaire à celui qu'on obtiendrait en utilisant Subversion. Néanmoins, les branches sont la vraie force de Git, et nous ne voulons pas nous passer de pouvoir passer d'une branche de travail à une branche de correction de bug rapidement, en local. Voici donc comment nous travaillons.
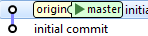
Avant de commencer à développer une nouvelle fonctionnalité ou un nouveau bug fix, on met à jour notre branche master locale :
master> git pull
![]()
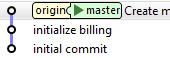
On crée ensuite sa branche de travail :
master> git checkout -b topic1
![]()

Et on effectue ensuite, en local, une série de commits successifs, jusqu'à avoir un code stable et intégrable dans master :
topic1> git add .
topic1> git commit
![]()
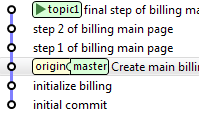
Bien sûr, ces commits peuvent se faire depuis l'IDE (IntelliJ IDEA dans notre cas).
Une fois ce travail intégrable, il s'agit de le réintégrer dans master. Mais nous voulons un historique linéaire, et les collègues ont eux aussi fait des changements dans origin/master de leur côté. Donc pas question de faire un merge. Rebase est la solution. On commence par rapatrier les changements effectués sur le serveur dans la branche master :
topic1> git checkout master
master> git pull
![]()
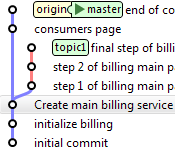
On revient ensuite dans notre branche de travail, qu'on rebase sur master. Un rebase consiste à réécrire les commits l'un après l'autre, comme si on était parti du code le plus récent sur master :
master> git checkout topic1
topic1> git rebase master
![]()
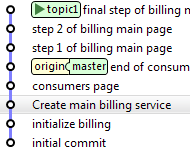
Dans cette étape, on peut choisir de fusionner nos commits ensemble pour n'en faire qu'un si on le désire, avec l'option -i. Il se peut qu'il y ait des conflits
à résoudre également. Dans ce cas, l'usage d'un outil graphique (l'IDE, TortoiseGit, SmartGit, etc.) devient une aide précieuse.
Une fois cette étape terminée, après avoir vérifié que le code compile toujours et que les tests passent, on peut réintégrer notre code dans master.
Si personne n'a modifié origin/master pendant le rebase, aucun problème. Mais mieux vaut s'en assurer. Dans ce cas, on recommence l'étape de rebase précédente.
topic1> git checkout master
master> git pull
![]()
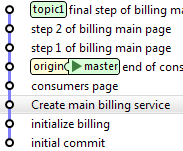
A ce moment, la branche topic1 est un descendant du dernier commit sur master. Il ne reste plus qu'à merger la branche sur master, et à la pousser sur origin. Le merge, dans ce cas, laissera l'historique linéaire, puisqu'il ne fera qu'avancer l'étiquette de la branche master dans les commits (fast-forward) :
master> git merge topic1
master> git push origin master
![]()
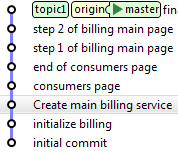
On peut ensuite continuer à travailler dans la branche topic1, s'il reste des choses à y faire, ou supprimer la branche et en créer une nouvelle pour la fonctionnalité suivante.
Gérer une branche de maintenance
Venons-en à présent à la gestion d'une branche de maintenance. Si un bug se présente sur l'application en production (ou en tests), il n'est pas toujours possible d'attendre que la dernière version, en cours de développement dans master, soit déployée. Il faut donc corriger ce bug dans la branche de maintenance, et s'assurer que la correction soit aussi intégrée dans master.
Certains changements, par contre, n'ont de sens que dans la branche de maintenance, et ne doivent pas être appliqués sur master. Par exemple, un changement de version des pom Maven, ou un backport d'un changement déjà présent dans master.
Subversion a un outil intéressant pour gérer ce problème. Toutes les révisions mergées de la branche de maintenance vers le trunk sont marquées comme telles.
Et on peut merger une ou plusieurs révisions avec l'option record-only.
Cette option permet de tracer que la révision, bien que ne devant pas être mergée, a été prise en compte.
Si après une nouvelle correction, on merge une nouvelle fois la branche de maintenance vers le trunk, cette révision sera détectée comme déjà mergée, et ne le sera donc plus.
Le cherry-pick de Git n'offre malheureusement pas cette fonctionnalité. Le merge de git est lui très différent de celui de Subversion, puisqu'en mergeant un commit, on merge aussi tous ses ancêtres. Et cela nous pose problème puisque, on l'a dit, on veut éviter que certains commits soient mergés dans master.
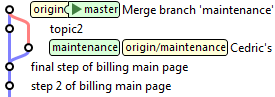
La solution : l'option -s ours de git merge. Cette option merge un commit, mais sans modifier du tout la branche cible. Supposons donc que Cédric fasse une première
correction dans la branche de maintenance, à intégrer dans master. Juste après son commit, il le merge dans master :
maintenance> git checkout master
master> git merge maintenance
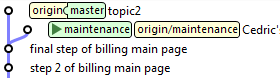
![]()
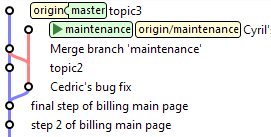
Supposons ensuite que Cyril fasse une release de cette branche de maintenance, et modifie donc la version des poms Maven. Ce commit ne doit pas être
réintégré dans master.
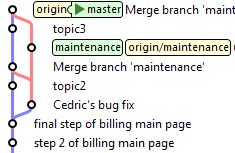
Il le marque donc comme tel avec l'option -s ours :
maintenance> git checkout master
master> git merge -s ours maintenance
![]()
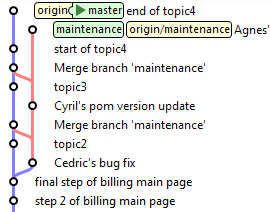
Agnès fait ensuite une nouvelle correction dans la branche de maintenance, à intégrer dans master :
maintenance> git checkout master
master> git merge maintenance
![]()
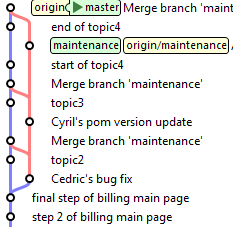
Ces merges successifs font ressembler les logs à une jolie couture, d'où le nom parfois utilisé de stitching pattern pour décrire ce motif.
Si tous les développeurs maîtrisent bien ce processus de report et s'appliquent à les effectuer immédiatement, le résultat est simple à analyser. On peut savoir d'un seul coup d'oeil aux logs ce qui a déjà et ce qui n'a pas encore été réintégré dans master. On peut aussi exécuter la commande suivante, qui devrait ne rien afficher si tout a bien été reporté
master> git log master..maintenanceVoilà le workflow qui nous a semblé optimal. N'hésitez pas à nous indiquer le vôtre, ou quelles astuces vous y avez apportées.

← Older post
Démarrer avec Git
Newer post →
Getting started with AngularJS
Our books on sale


Next training sessions
- From Mar 2 to Mar 5, 2026Angular: Zero to Ninja(remote)
- From Mar 16 to Mar 19, 2026Angular: Ninja to Hero(remote)
- From Apr 20 to Apr 23, 2026Vue: Zero to Ninja(remote)