Generate REST API documentation with Asciidoctor and Gradle
Generating documentation for a Java API is quite easy. Javadoc is a great and easy to use tool, integrated with every Java build tool, and produces a result that every Java developer is (or should be) comfortable with.
Generating documentation for a REST API is not as easy. You can implement a RESTful backend in any language you can imagine. Once you have chosen one (Java, in our case), the way you define it and implement it depends on the frameworks you choose: JAX-RS, Spring MVC, etc. Even assuming you have a tool understanding your framework, it also has to understand how your JSON serializer (Jackson, in this case) is configured and works. And if you use annotations to define your validation constraints, it also has to understand them. All in all, automating the documentation generation of a REST API is much harder than doing so for a Java API.
We did some experiments with Swagger, but were not really satisfied with the result. It has good points: language and framework-agnostic specification, automatic generation from code and annotations, JSON structure descriptions and examples, possibility to send GET and POST requests directly from the documentation.
But its Spring MVC integration doesn't handle all the signatures of the Spring MVC controller methods, the generated validation constraints are incorrect, and the end result is a bit rough. It's also non-trivial to have an offline version of the documentation.
There are goods reasons why popular REST API documentations like the Twitter API are not automatically generated, but carefully hand-crafted. So we finally decided to go this way, and this post describes how we did it.
Asciidoc
First af all, we wanted to be free to organize the documentation as we wanted, to provide introductory paragraphs about the general conventions, etc. Being able to generate it in various formats (HTML, PDF, etc.) is also something we found useful. And an automatically generated table of contents is great as well. So we decided to go with Asciidoc and, more specifically, Asciidoctor. A typical service documentation looks like this in our Asciidoc document:
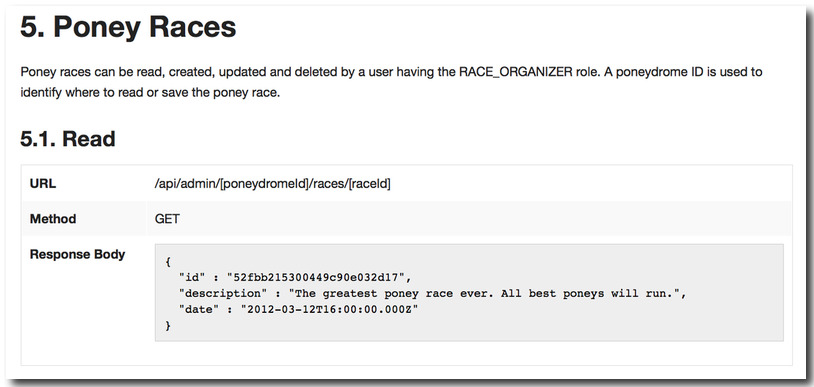
== Poney Races
Poney races can be read, created, updated and deleted by a user having the
RACE_ORGANIZER role. A poneydrome ID is used to identify where to read
or save the poney race.
=== Read
[cols="h,5a"]
|===
| URL
| /api/admin/[poneydromeId]/races/[raceId]
| Method
| GET
| Response Body
| include::{snippetDir}/race.json.adoc[]
|===You can add any information you like, in any format you like, in the documentation. This is a real advantage that allows making your documentation readable and understandable. But even more than the URLs, the HTTP methods and status codes, what matters is the nature and format of the data accepted or returned by the services. And this is where we automated it partially, to make sure it conforms to the reality of the actual API, and to avoid having to hard-code JSON structures in the document.
JSON snippets generation
The magic is thus in the include block in the snippet above. The race.json.adoc file is generated and contains an example JSON structure.
To generate it, we use Java code that creates instances of Java objects that are actually returned by the service, and serialize them using the
same Jackson mapper, configured the same way as in the actual application (except for the indentation).
So we simply have a class that contains methods like the following:
private PoneyRace poneyRace() {
PoneyRace race = new PoneyRace();
race.setId(new ObjectId().toString());
race.setDescription("The greatest poney race ever. All best poneys will run.");
race.setDate(DateTime.parse("2012-03-12T16:00:00Z"));
return race;
}Every object that needs to be converted to JSON and included in the documentation is generated by a method such as the one above, and written to a file using the simple method below:
private void write(String fileName, Object o) throws IOException {
File file = new File(destinationDirectory, fileName + ".json.adoc");
try (PrintWriter out = new PrintWriter(new OutputStreamWriter(new FileOutputStream(file), StandardCharsets.UTF_8))) {
out.println("[source,javascript]");
out.println("----");
out.println(objectMapper.writer().writeValueAsString(o));
out.println("----");
}
}And here is how it looks like once generated:
Gradle to assemble everything
To generate the complete documentation, it's now only a matter of compiling and running the class generating the include files, and to invoke Asciidoctor with the appropriate options in order to generate the documentation where we want it. We integrated this task in our Gradle build:
def restApiTmpDir = file("$buildDir/tmp/rest-api")
def restApiOutputDir = file("$buildDir/doc/rest-api")
task generateRestApiDocSnippets(type: JavaExec) {
outputs.dir restApiTmpDir
classpath sourceSets.main.runtimeClasspath
main 'com.ninja_squad.secretproject.doc.DocumentationGenerator'
args restApiTmpDir
}
task restApiDoc(type: Exec) {
group = 'documentation'
description = 'Generates the REST API documentation.'
dependsOn generateRestApiDocSnippets
inputs.dir file('src/main/doc/rest-api')
inputs.dir restApiTmpDir
outputs.dir restApiOutputDir
executable 'asciidoctor'
args file('src/main/doc/rest-api/rest-api.adoc')
args '-D', restApiOutputDir
args '-a', "snippetDir=${restApiTmpDir}"
args '-a', "stylesDir=${file('src/main/doc/rest-api/stylesheets')}"
args '-a', "imagesDir=${file('src/main/doc/rest-api/images')}"
}Conclusion
Is this strategy perfect? Nope. You have to maintain the documentation as you maintain the code. Changing an URL in the code means also changing it in the documentation. But it does a good job, in a simple and flexible way, without having to fight with a tool which thinks it knows more than you do.

← Older post
Workflow, Pull Requests & Code Reviews
Newer post →
The poor man's JRebel
Our books on sale

