Stop with serialVersionUID!
Je ne compte plus les projets où la moitié des classes commencent par le fameux
private static final long serialVersionUID = 875713023L;
et ça m’énerve !
Alors bien sûr, les intentions des développeurs sont louables. L’IDE (Eclipse, I’m looking at you)
émet un avertissement disant que la classe est sérialisable mais n’a pas de serialVersionUID. Pour
avoir un avertissement de moins et faire plaisir à leur IDE, ils ajoutent un serialVersionUID à la classe.
Il y a un autre moyen de ne plus avoir d’avertissement : désactiver cette règle dans les options de compilation de l’IDE. Comme je suis sympa, je vais même vous dire où ça se trouve (dans Eclipse) :
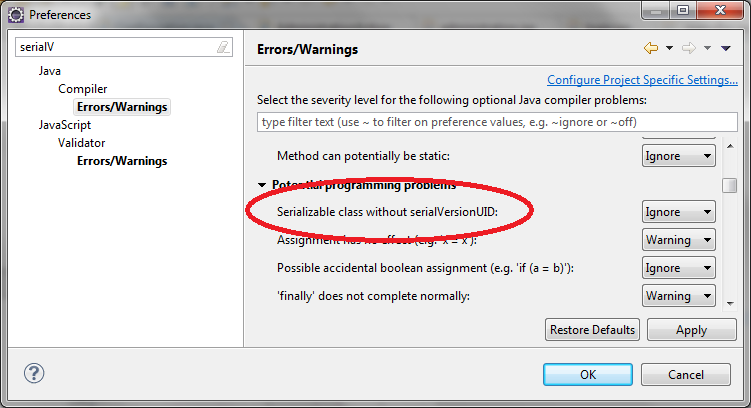
Maintenant, ce qui serait encore mieux, ce serait de comprendre à quoi cette constante sert, pourquoi elle est parfois nécessaire, et pourquoi l’immense majorité du temps, elle ne l’est pas et ne fait que rajouter du bruit dans les sources.
Explication
Quand un objet est sérialisé, il est transformé en suite de bytes. Ce flux binaire est destiné à être retransformé, plus tard ou ailleurs, en une copie de l’objet original. On peut par exemple l’envoyer sur le réseau à destination d’un client. Ou on peut l’enregistrer sur disque pour être désérialisé plus tard.
Lorsque l’objet est sérialisé, en plus du nom
de la classe de l’objet, la version de cette classe (la valeur de serialVersionUID) est aussi écrite avant l’état
à proprement parler de l’objet. Cela permet, à la lecture, de détecter un conflit entre la classe de l’objet sérialisé
et la classe présente dans le classpath à la désérialisation.
Si aucun serialVersionUID n’est défini dans la classe, la JVM
en calcule un automatiquement à partir des
noms de classe, d’interfaces, des champs et méthodes contenus dans la classe. Si la classe est modifiée
(par exemple, des champs ou des méthodes sont ajoutés, supprimés, ou permutés), relire l’objet sérialisé ne fonctionnera pas :
la JVM va comparer le serialVersionUID présent dans la suite de bytes avec celui généré pour la classe chargée en mémoire,
va détecter une différence et va lever une InvalidClassException.
Ajouter un serialVersionUID à la classe, et lui laisser la même valeur même après une modification de la classe
revient à dire : je sais que la classe a changé, mais je garantis que les changements apportés sont compatibles et permettent de
lire une ancienne version à partir de la nouvelle, et vice-versa.
Le problème, c’est qu’il ne suffit pas de le dire : il faut aussi être capable de le faire ! Et le faire, ça nécessite de savoir
quels changements sont compatibles et quels changements ne le
sont pas.
Ca nécessite de réfléchir très attentivement à chacune des évolutions apportées à la classe. Ca nécessite éventuellement
d’implémenter des méthodes telles que readResolve(), readObject(), writeObject() pour conserver la compatibilité.
Et curieusement, ça, personne ne le fait. Au mieux, tenter de lire une ancienne version de l’objet va donc lever une exception.
Au pire, ça va fonctionner, mais retourner un objet dans un état complètement incohérent, incapable de remplir son contrat.
La plupart du temps heureusement, la sérialisation n’est pas utilisée comme mode de persistance à long terme, devant être capable de s’adapter à des changements de structure des classes. Lorsqu’elle est utilisée comme moyen de communication, les deux parties (le client et le serveur) partagent la même version des classes. Il est rare de déployer un serveur en version 1.2 qui doit toujours pouvoir parler à des clients en version 1.1.
Donc, TL;DR : si vous ne vous servez pas de la sérialisation comme moyen de persistance à long terme, et si vos clients et votre
serveur sont déployés de manière homogène, désactivez cette option de compilation et ne mettez pas de champ serialVersionUID
dans vos classes. Un bon coup de regexp-replace, et vous pouvez même les enlever.

Become a Ninja with Angular

Pay what you want and support charity!
Become a Ninja with Vue 3

Pay what you want and support the Vue team!
Formations
certifiées Qualiopi
21-24/05 à distance
25-28/03 à distance
10-13/06 à distance
27-30/05 à distance

